
Orthography-based Language Modelling for Speech Recognition.
Automatic speech recognition (ASR) is a branch of natural language processing (NLP) that uses computer algorithms to convert speech data to its corresponding textual representation in the form of a phone/word sequence [1]. One of the major components of an ASR system, as shown on Figure 1, is a language modelling (LM) component that is concerned with creating models of phone/word sequences to capture regularities of a language such as syntactic, semantic and pragmatic characteristics [2] [3]. When developed, the language models are used by a speech recogniser to determine the likelihood of unknown word sequences to be valid or legal sentences of the language. The more knowledgeable these models are about the target language and/or the recognition task, the better their determination of the most likely phone/word sequences matching the utterances.
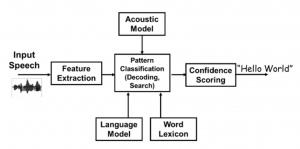
Figure 1: Automatic speech recognition [4]
This study investigates the influence that the orthography (or conventional writing system) of a language has on the quality of language models created for speech recognition. Different language modelling approaches and/or recipes that take into account the effect that a unique language structure has on the performance of its language models, have been recommended for different languages. Unique language structures such as rich morphology, high inflexion, flexible word order, and compounding of words by different languages have been investigated [5] [6] [3] [7] [8] [9] [10] [11]. In this study we focus on the unique conjunctive and disjunctive writing systems of IsiNdebele (endonym for Ndebele) and Sepedi (endonym for Pedi) respectively, in relation to language modelling. Towards this goal, different language models are created and analysed.
In this paper, we report the results from three preliminary language modelling experiments conducted using the Lwazi and NCHLT text corpora, on the SRILM toolkit. The language modelling results indicate the need to model the writing systems of the chosen languages differently.
Thus far, we have conducted only three of the planned ten experiments. For experiments 1 and 2, we used default parameters to develop the LM models up to n-gram order 6; and up to order 20 for experiment 3. We used LM smoothing methods supported by the toolkit in the experimentation process. In all the experiments, either the Ndebele or Pedi test data set were used for testing the developed models.
In Experiment 1, the text was normalised in different ways and resulted in the following versions: original tagged text without start and end sentence tags – e.g., <s> and </s>; normalised text with the original tocorpus.pl [12] script that does standard normalisation; normalised with modified tocorpus.pl to remove one letter annotation tags; normalisation with modified tocorpus.pl to also remove more than one letter annotation tags; conversion of normalised text to uppercase; conversion to mixed lower and uppercase normalised sentence streams; and normalised text with added sentence boundary markers <s> and </s>. The versions were numbered 1, 2, 3.1, 3.2, 4.1, 4.2, and 5 respectively. The aim from this experiment was to arrive at the normalisation prescription that can be prescribed for LM development of the text for the chosen languages.
To determine the gain, if any, that may be derived from borrowing data from closely related languages, Experiment 2 combined or polled text data from different sources. For both languages, one combination is from both Lwazi and NCHLT texts, and the other is from texts of languages in the same cluster (Nguni or Sotho). Thus, the second combination will have further sub-combinations of Lwazi, NCHLT, and Lwazi+NCHLT.
In investigating high-order ngrams for the text of the two languages, the third experiment developed language models up to n-gram order 20. For each language, the experiment considered the different sized text in Lwazi, NCHLT, Lwazi+NCHLT, and cluster grouped text.
In analyzing the results from the three experiments, we observe that there is a need to approach language modelling of the two writing systems, conjunctive and disjunctive, differently. In particular, Experiment 1 (through Table 1) showed that normalized text with removed annotation tags develops better models.
From Experiment 2, by combining the Lwazi and NCHLT corpora, the recognition domain was widened and the size of the text corpus increased considerably. Table 2 indicates that, when compared to Experiment 1 NCHLT language models, there was an increase of about 3.9 in perplexity (PPL) for Pedi, and a significant drop of 10.3 for Ndebele.
High-order n-grams above the standard trigrams appear, through Figure 3, to be suitable for modelling both the under- resourced Pedi and Ndebele languages. However, the high order appears to be bounded to n = 6, after which the performance remains stable or deteriorates a bit throughout. For Pedi, low PPL ngram language models were pentagrams and hexagrams. Trigrams and quadrigrams were observed to better model the Ndebele text.
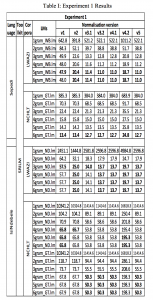
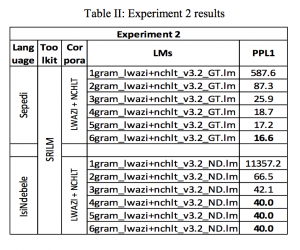
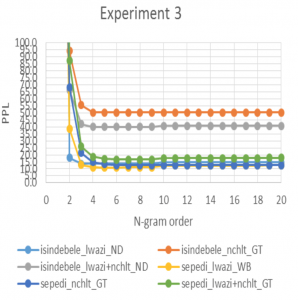
Figure 2: Experiment 3 results
Looking forward, it will be interesting to observe and learn from the results of the other planned experiments, and the performance of the LMs in an ASR system.